01 · From Text to Probabilities
GENE 46100 — Unit 01
2026-04-12
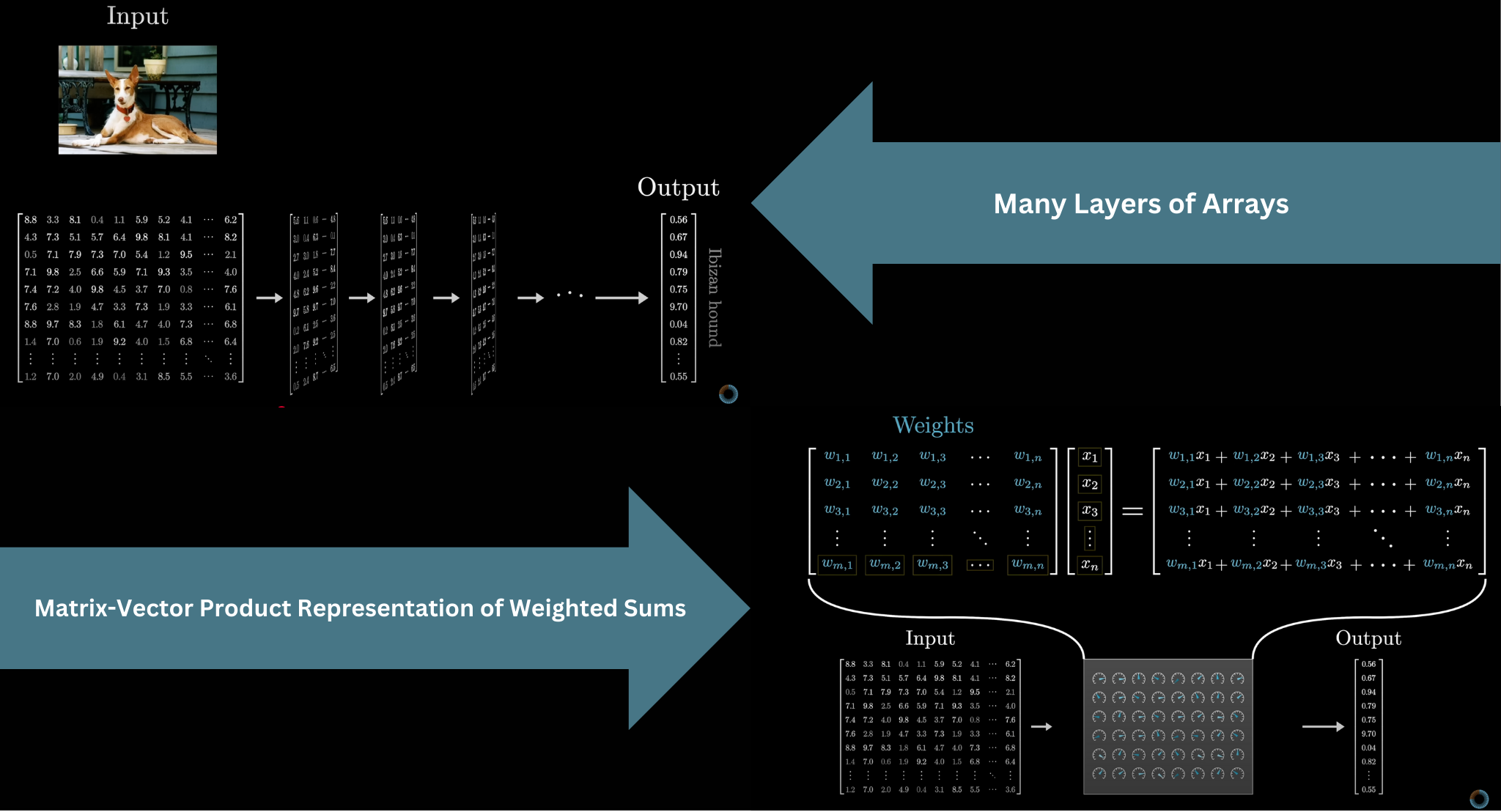
The transformer pipeline
Before diving in: here is the full flow from text to prediction.
- Text → tokens
- Tokens → vectors via W_E
- Vectors pass through Attention → MLP blocks, repeated
- Final vector → scores via W_U
- Scores → probabilities via softmax
- Sample next token
Source: 3Blue1Brown — What is a GPT?
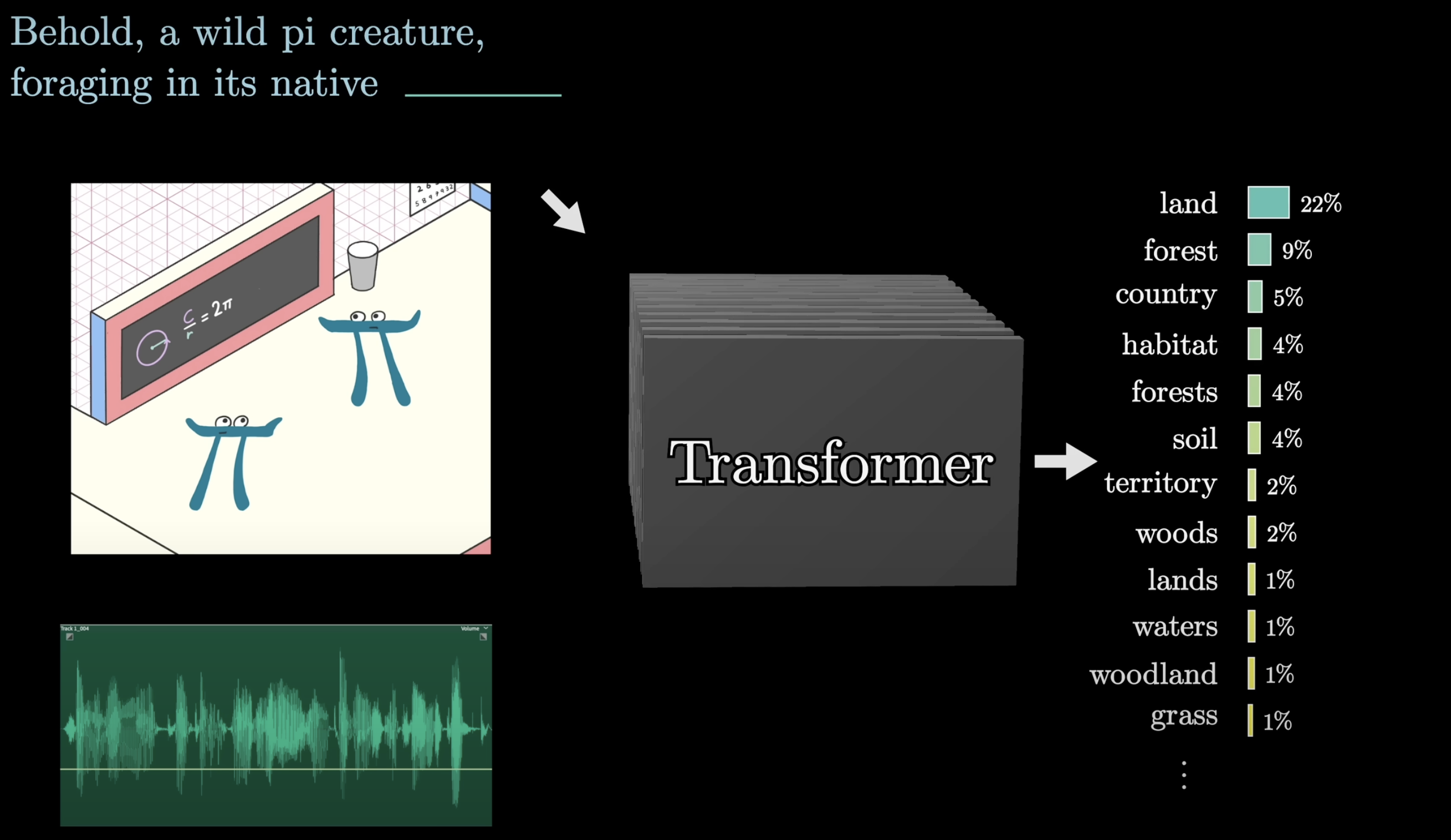
Text breaks into chunks: tokens
Before any math, text is split into tokens — the atomic units the model works with.
Each token maps to a vector — a list of numbers. This is what the model actually computes with.
Source: 3Blue1Brown — What is a GPT?
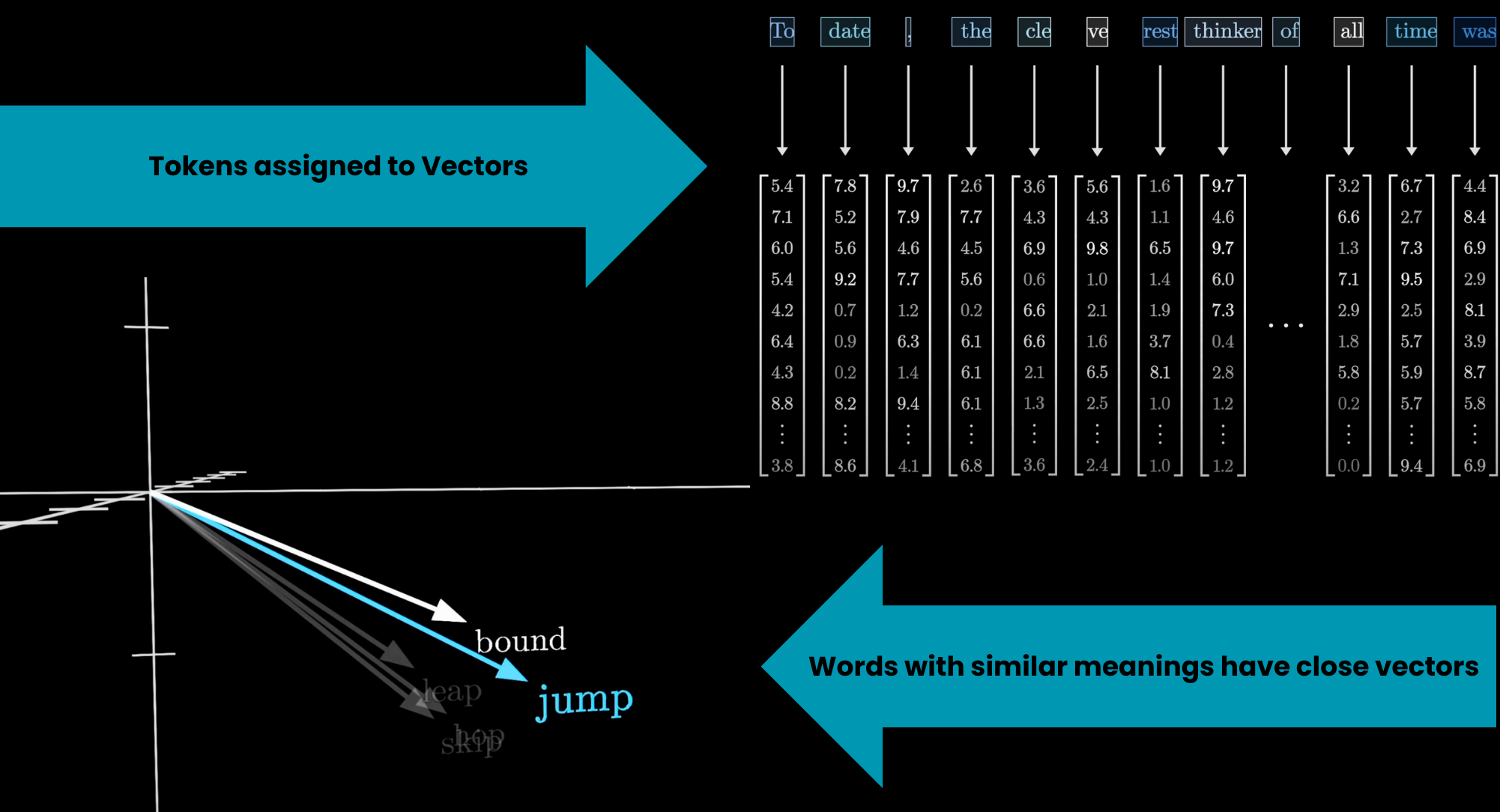
Tokens become arrays of numbers
The numbers start as a lookup (same token = same vector). Context changes them later.
Source: 3Blue1Brown — What is a GPT?
The embedding matrix W_E
The first thing a transformer does: look up each token in the embedding matrix W_E.
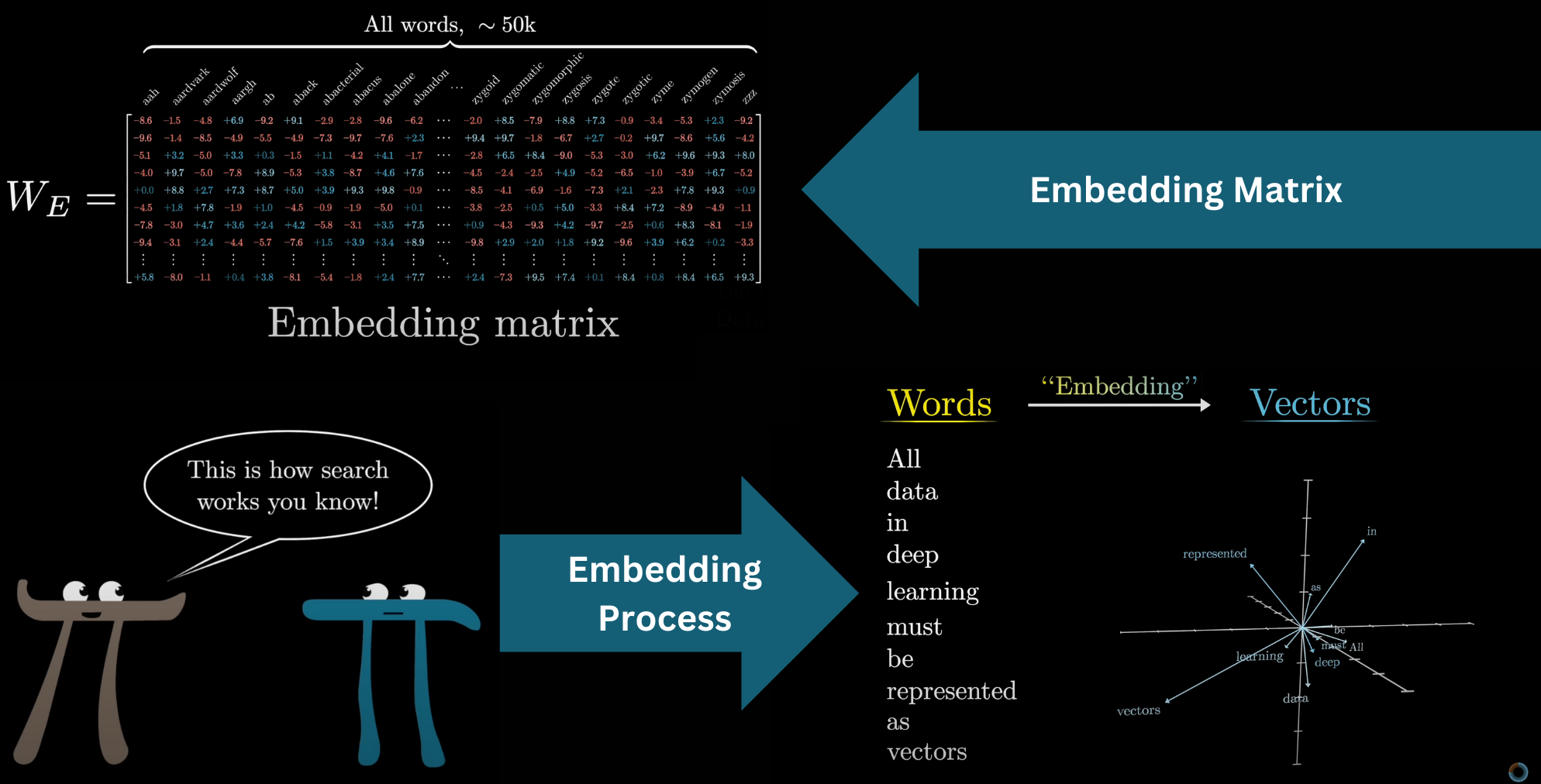
GPT-3: vocabulary = 50,257 tokens × 12,288 dimensions → 617 million weights just in this one matrix.
Source: 3Blue1Brown — What is a GPT?
Similar meanings cluster in space
Word vectors are not random. Words with similar meanings end up close together in the high-dimensional space.

Source: 3Blue1Brown — What is a GPT?
Directions encode meaning
The difference between “man” and “woman” vectors is similar to the difference between “king” and “queen.”
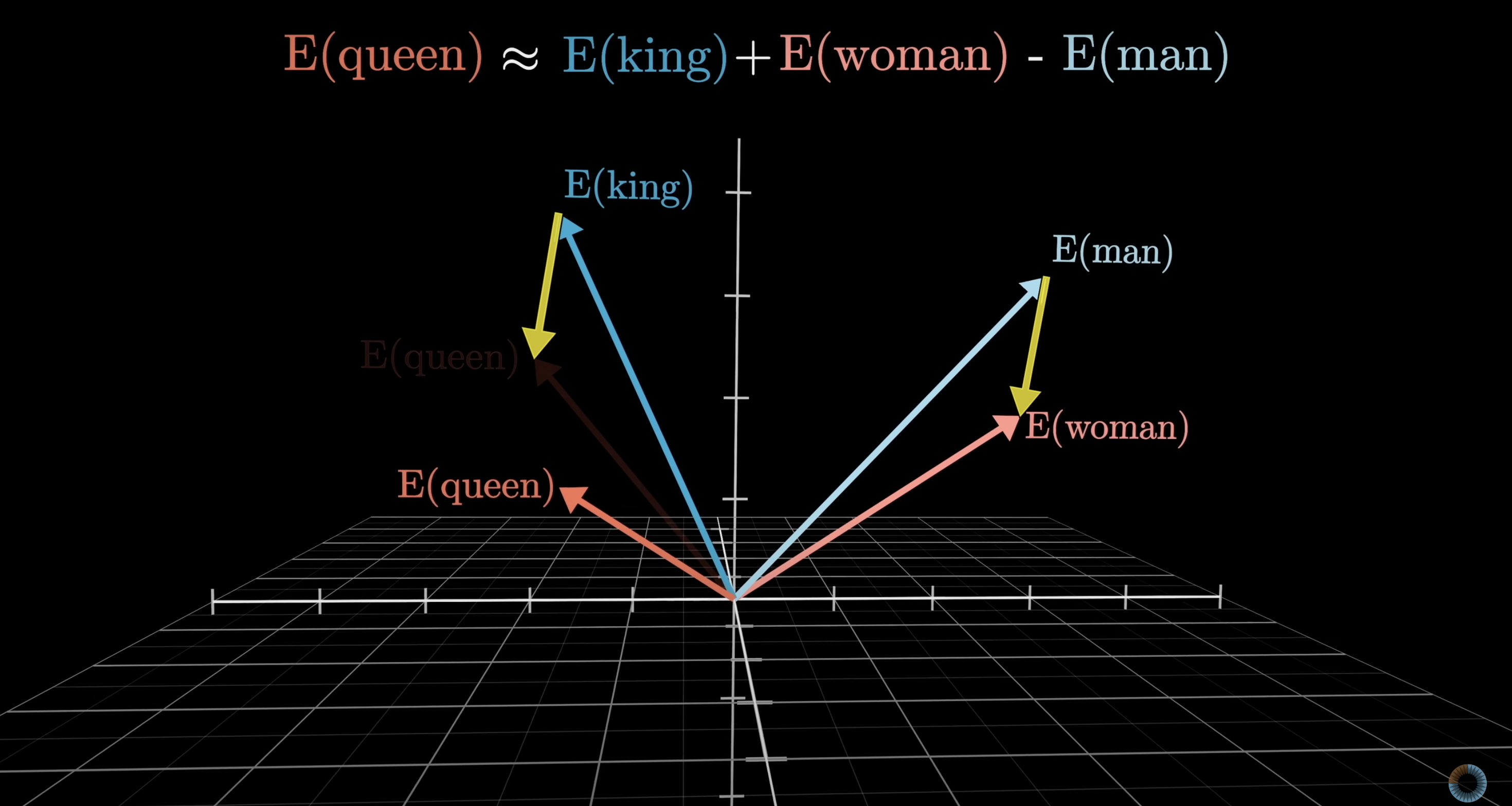
There is a gender direction in embedding space — not programmed in, learned from text.
Source: 3Blue1Brown — What is a GPT?
Semantic directions are consistent
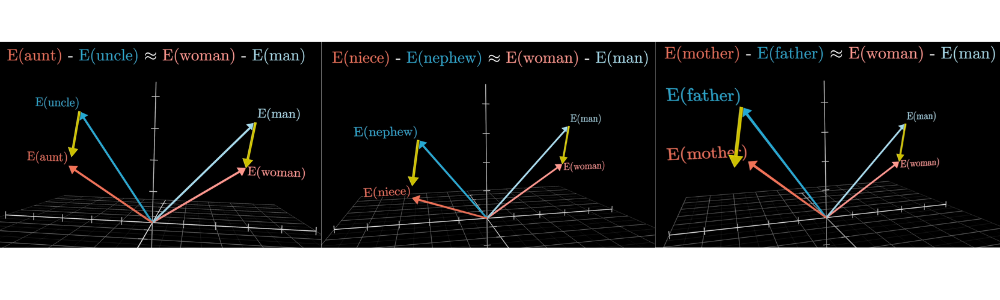
The same direction that encodes gender also generalizes across many word pairs — it’s a stable geometric feature of the space.
Source: 3Blue1Brown — What is a GPT?
Geography works too
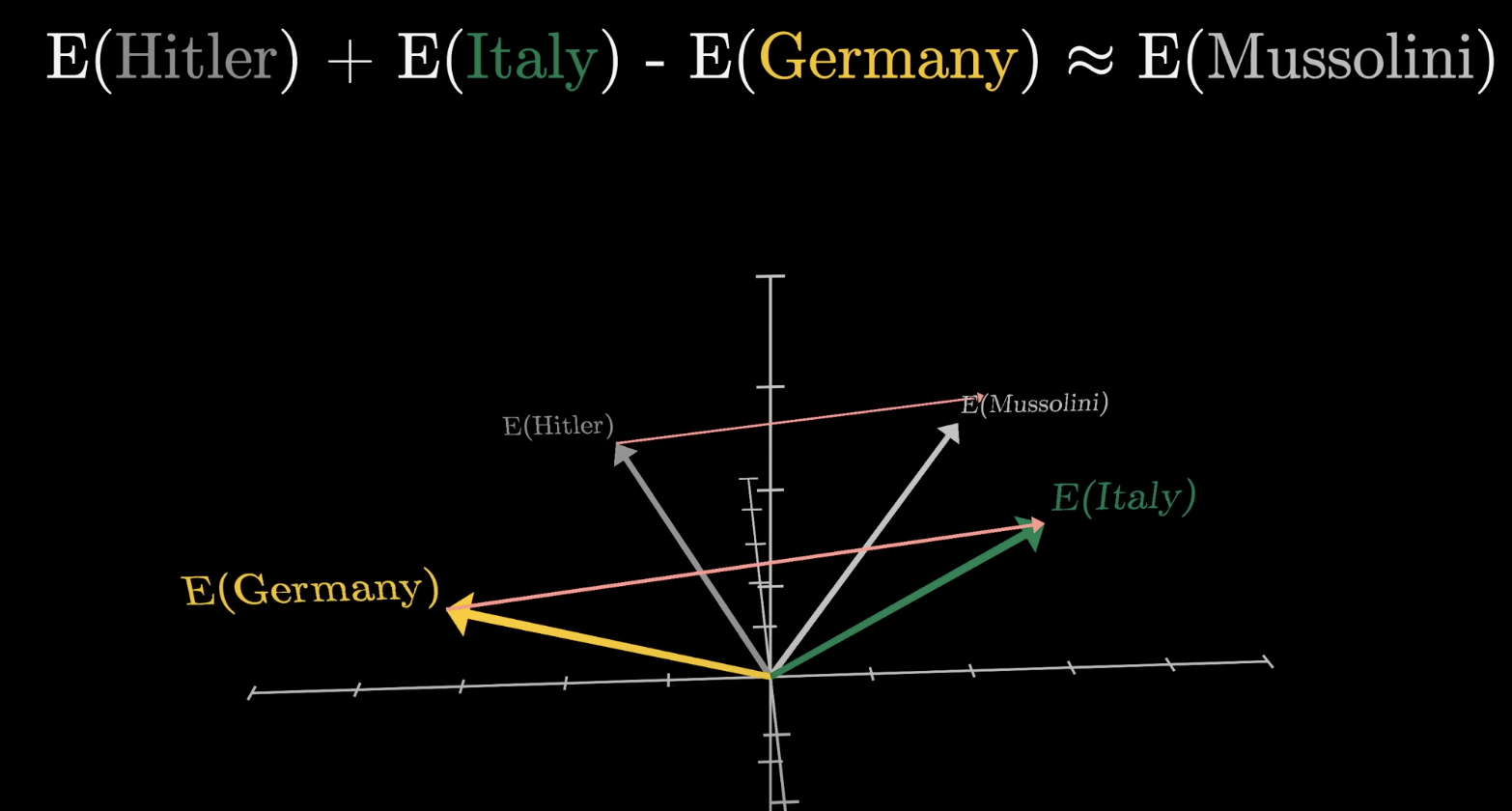
The difference between country and capital vectors is consistent across examples.
Subtracting “Germany” from “Italy” and adding to “Hitler” lands near “Mussolini.” Meaning lives in geometry.
Source: 3Blue1Brown — What is a GPT?
Dot product = measure of alignment
The dot product is how the model asks: how similar are these two vectors?
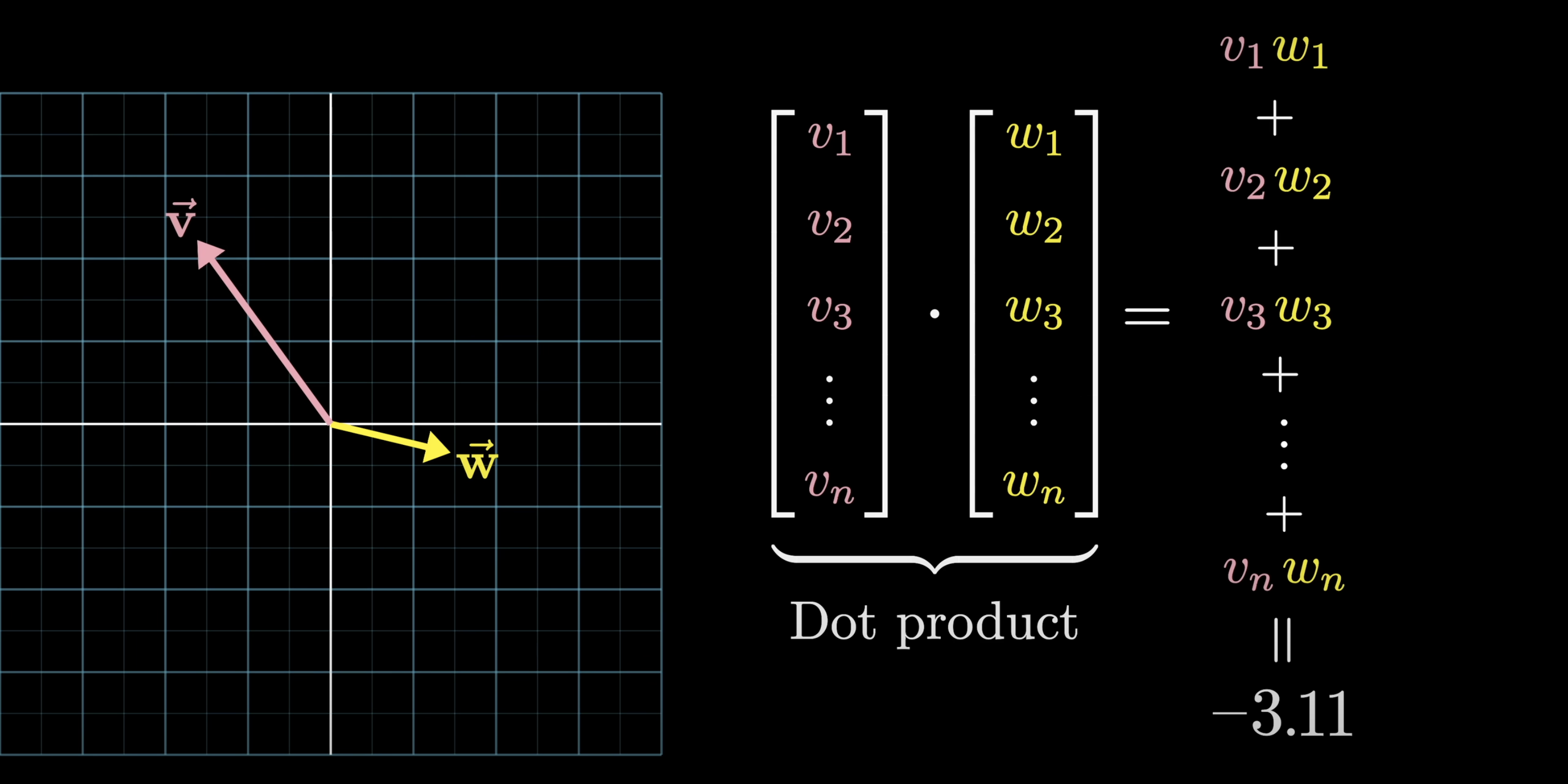
- Positive → vectors point in the same direction (similar)
- Zero → perpendicular (unrelated)
- Negative → opposite directions (different)
Source: 3Blue1Brown — What is a GPT?
Dot products detect semantic directions
The plurality direction plur = E(cats) − E(cat) captures what “plural” means geometrically.
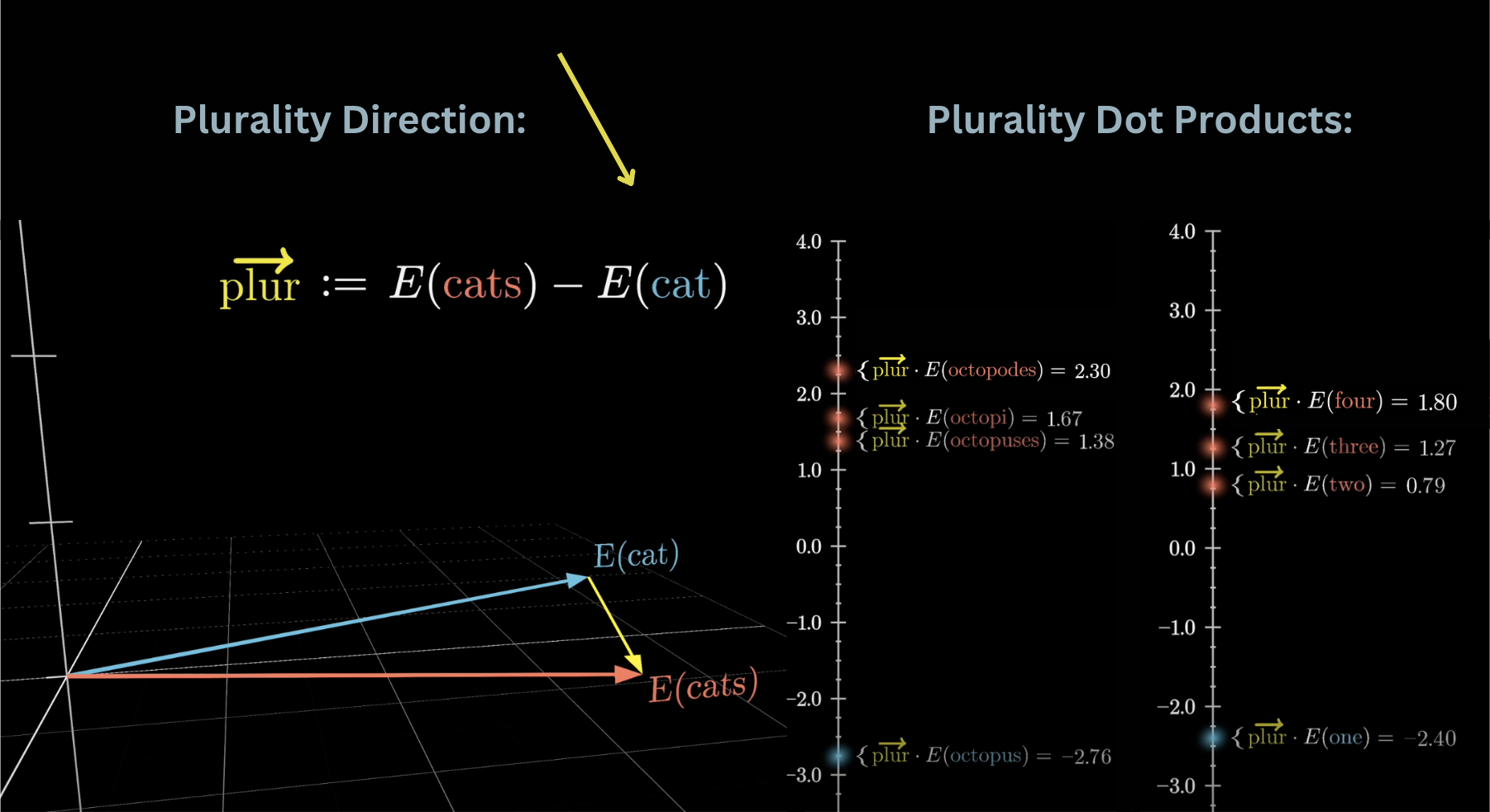
Octopodes / octopi / octopuses score high (plural); “one” scores negative (singular).
This same principle drives attention: queries dot-producted with keys measure relevance.
Source: 3Blue1Brown — What is a GPT?
Context window: what the model sees
The model processes a fixed window of tokens at once.
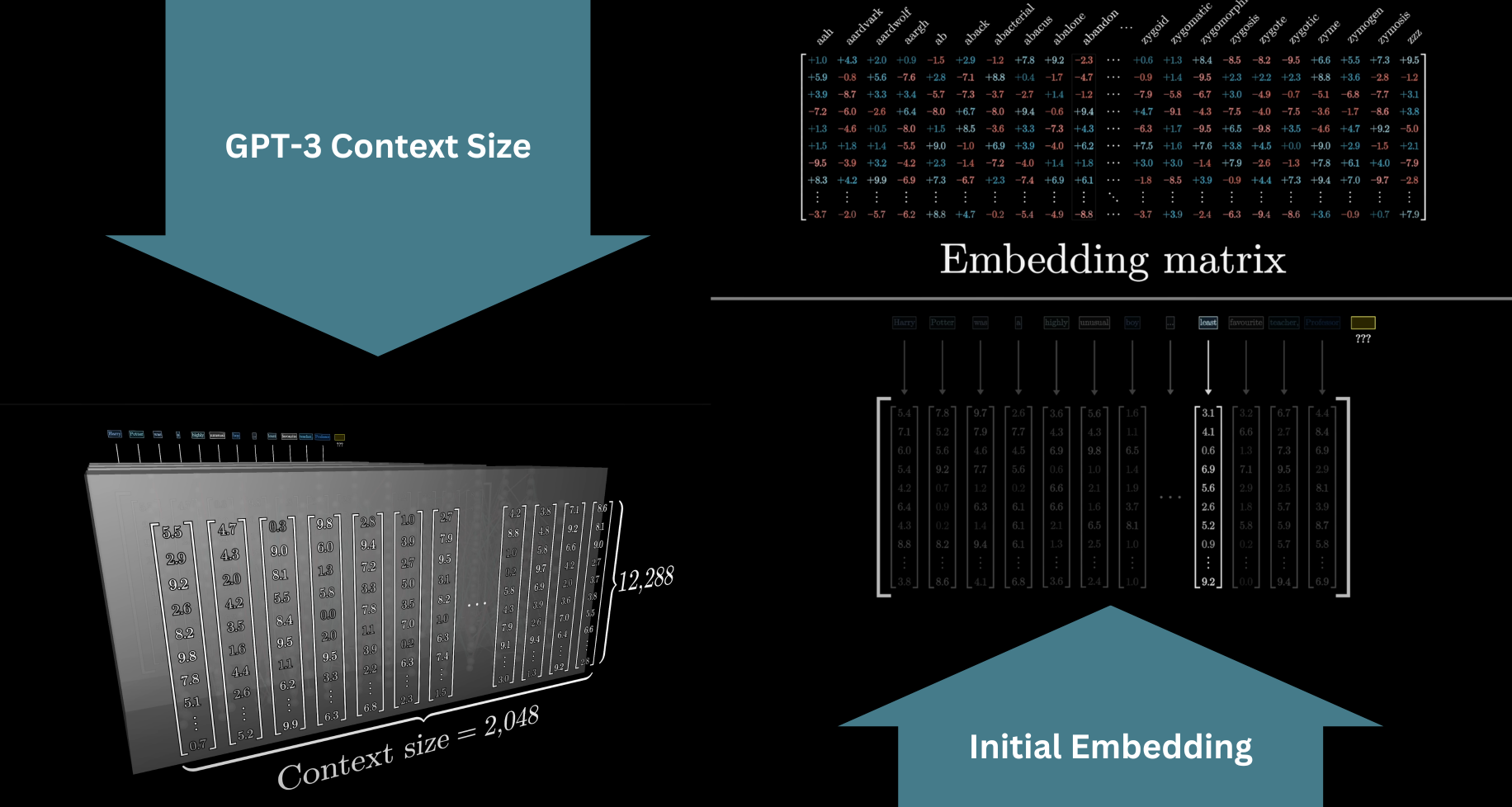
- GPT-3 context = 2,048 tokens
- Modern models extend this to 100k+
- Everything outside the window is invisible to the model
Source: 3Blue1Brown — What is a GPT?
Same word, different meaning
Initial vectors encode the word alone. As vectors flow through the network, they absorb context.
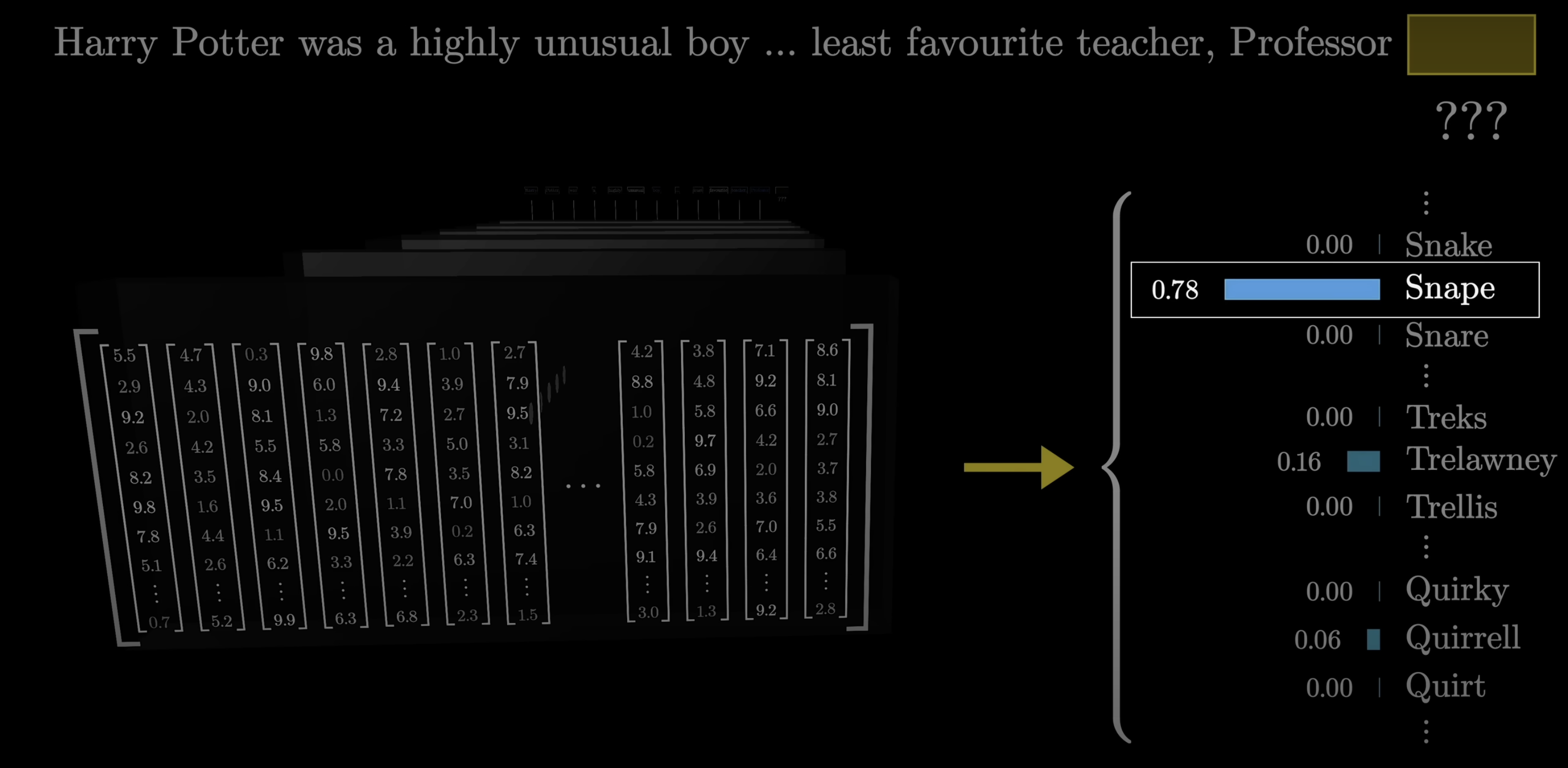
- Same word → same starting vector
- Context flows through the network, updating each vector
- “Snape” near potions → shifts toward one region of meaning
- “Snape” near betrayal → shifts toward another
- Same starting point, different destination
Source: 3Blue1Brown — What is a GPT?
Getting back to words: W_U
After all transformer layers, the final vector must become a probability distribution over the vocabulary.
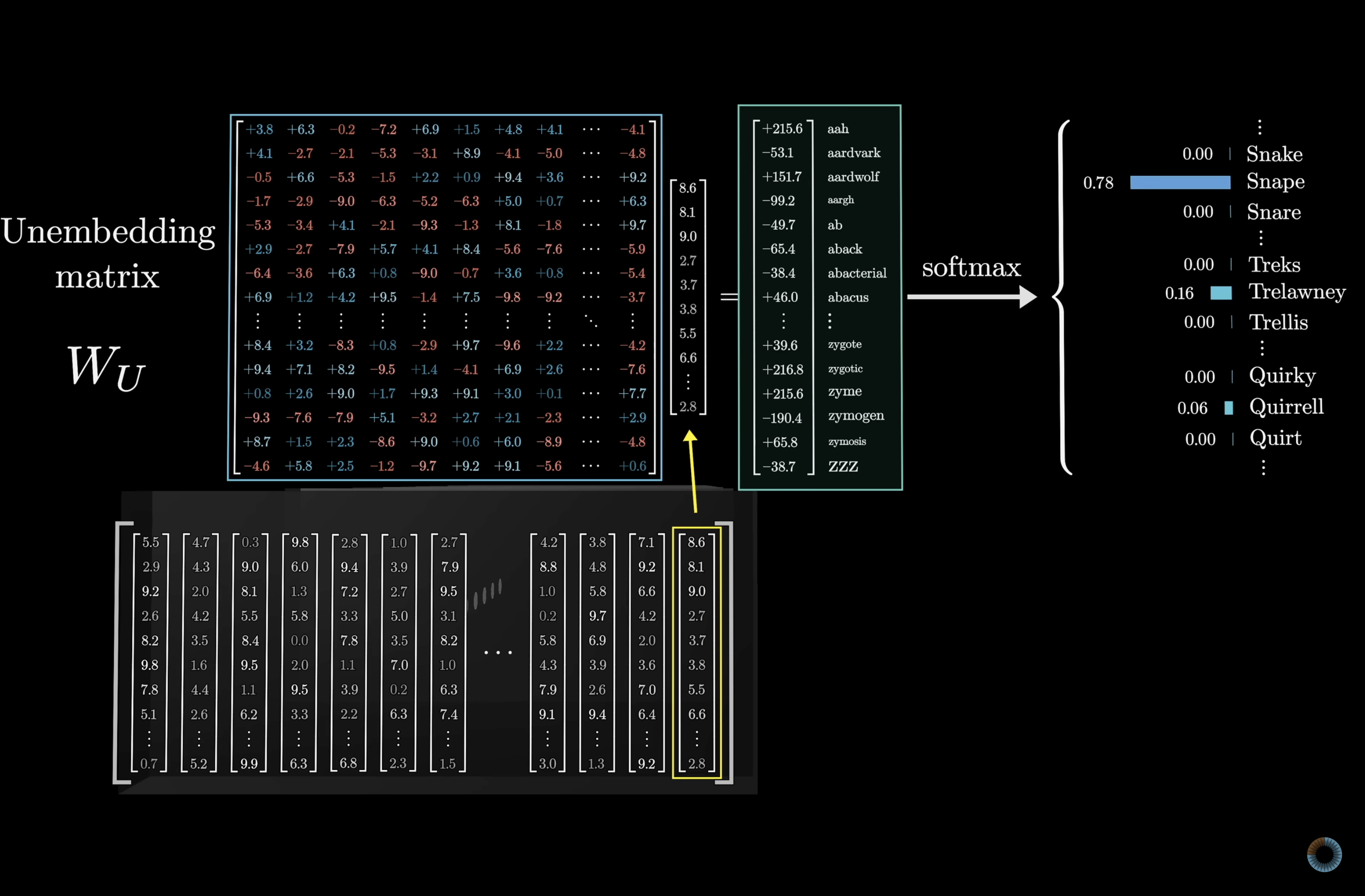
The unembedding matrix W_U maps the final vector back to one score per vocabulary token. Same dimensions as W_E, transposed.
Source: 3Blue1Brown — What is a GPT?
Logits: the raw scores
The output of W_U is a vector of 50,000+ raw scores — one per token in the vocabulary.
These scores are called logits — they can be any real number: negative, large, small.
They are not yet probabilities. That is softmax’s job.
Source: 3Blue1Brown — What is a GPT?
Softmax: from scores to probabilities
Raw scores (logits) can be any number. Softmax converts them into a valid probability distribution.
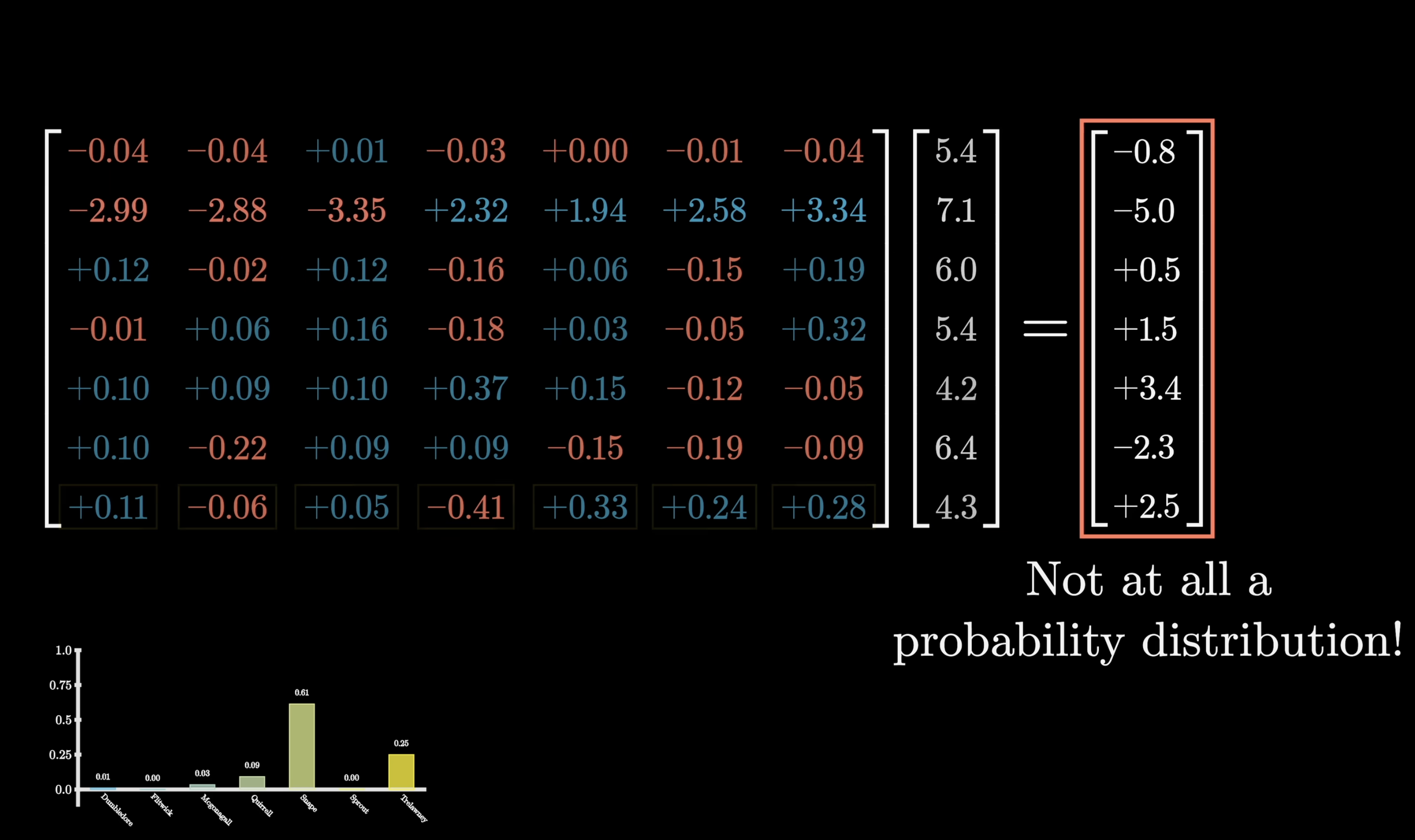
\[\text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}}\]
- \(e^{x_i}\) — forces all values positive
- \(\sum_j e^{x_j}\) — normalisation constant
- Divide → outputs sum to 1
Source: 3Blue1Brown — What is a GPT?
How softmax behaves
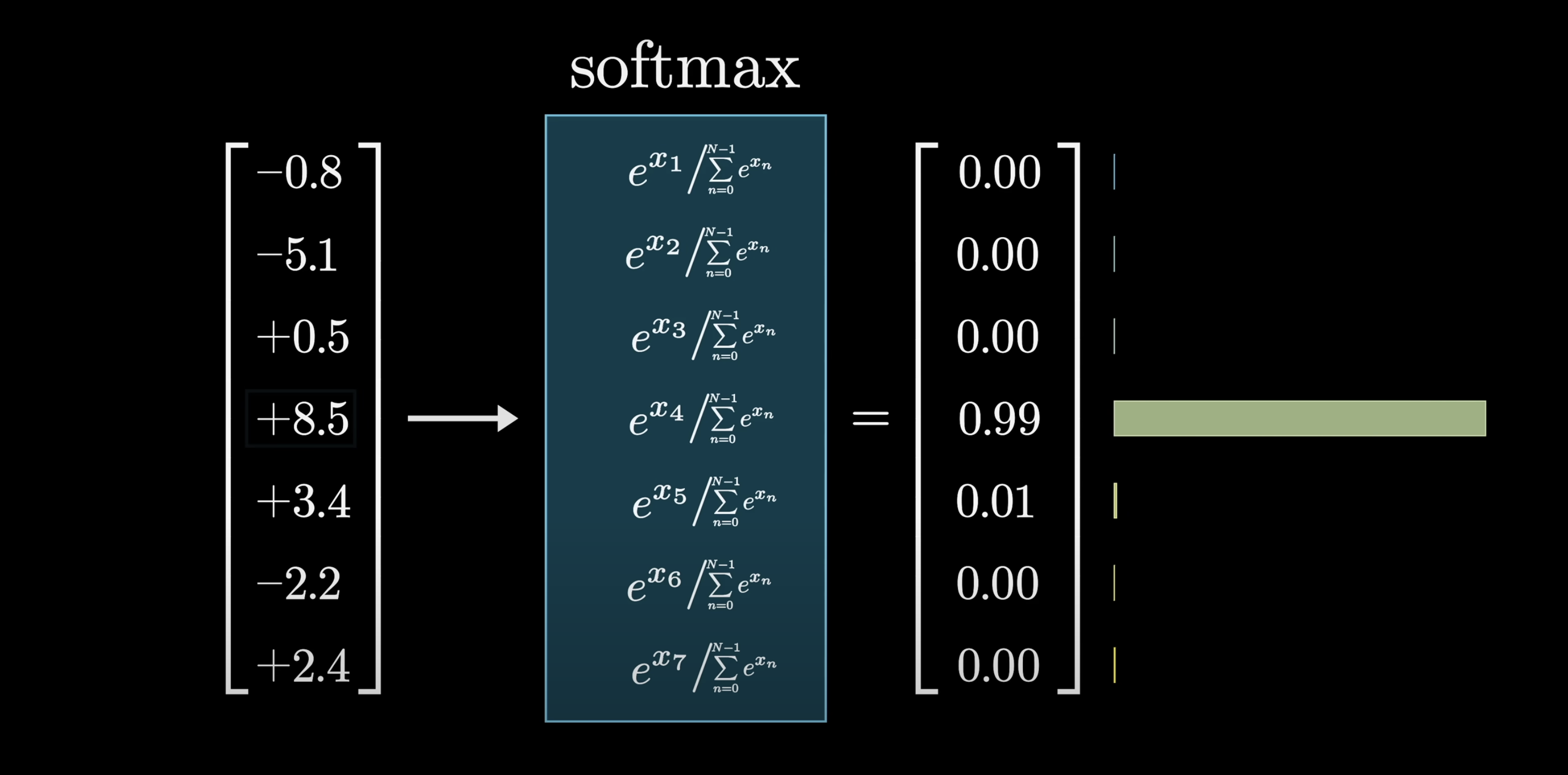
Large differences between scores → one token dominates.
Small differences → distribution spreads out.
Source: 3Blue1Brown — What is a GPT?
Temperature: dialing confidence up or down
Divide logits by temperature \(T\) before softmax:
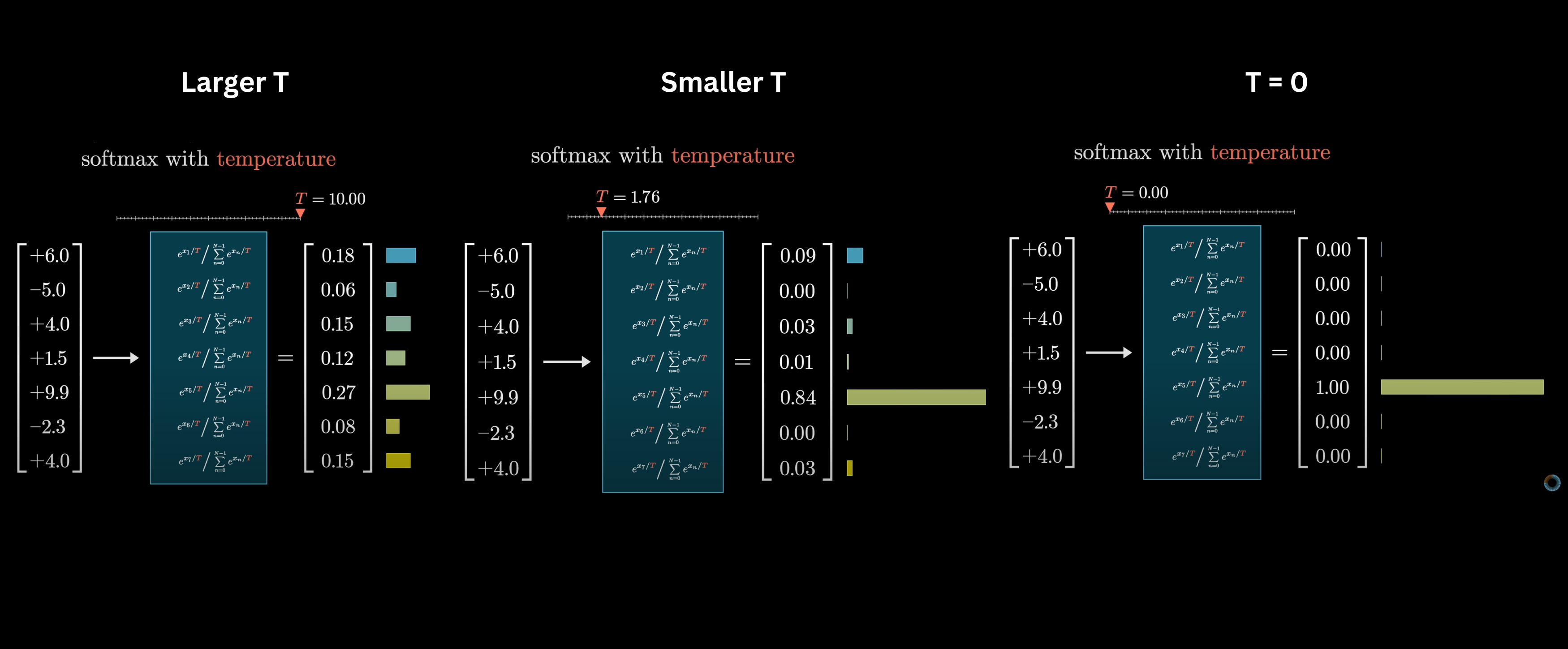
| \(T\) | Effect |
|---|---|
| \(T < 1\) | Sharper — model is more decisive |
| \(T = 1\) | Default |
| \(T > 1\) | Flatter — more random, more creative |
| \(T \to 0\) | Always picks the top token (greedy) |
Source: 3Blue1Brown — What is a GPT?
The full prediction pipeline
Token → W_E → transformer layers → W_U → softmax → sample next token.
Each pass produces one token. Repeat to generate text.
Source: 3Blue1Brown — What is a GPT?
What attention does
We have vectors. We have dot products. Attention uses both: each token’s vector queries other tokens’ keys to decide how much to attend.
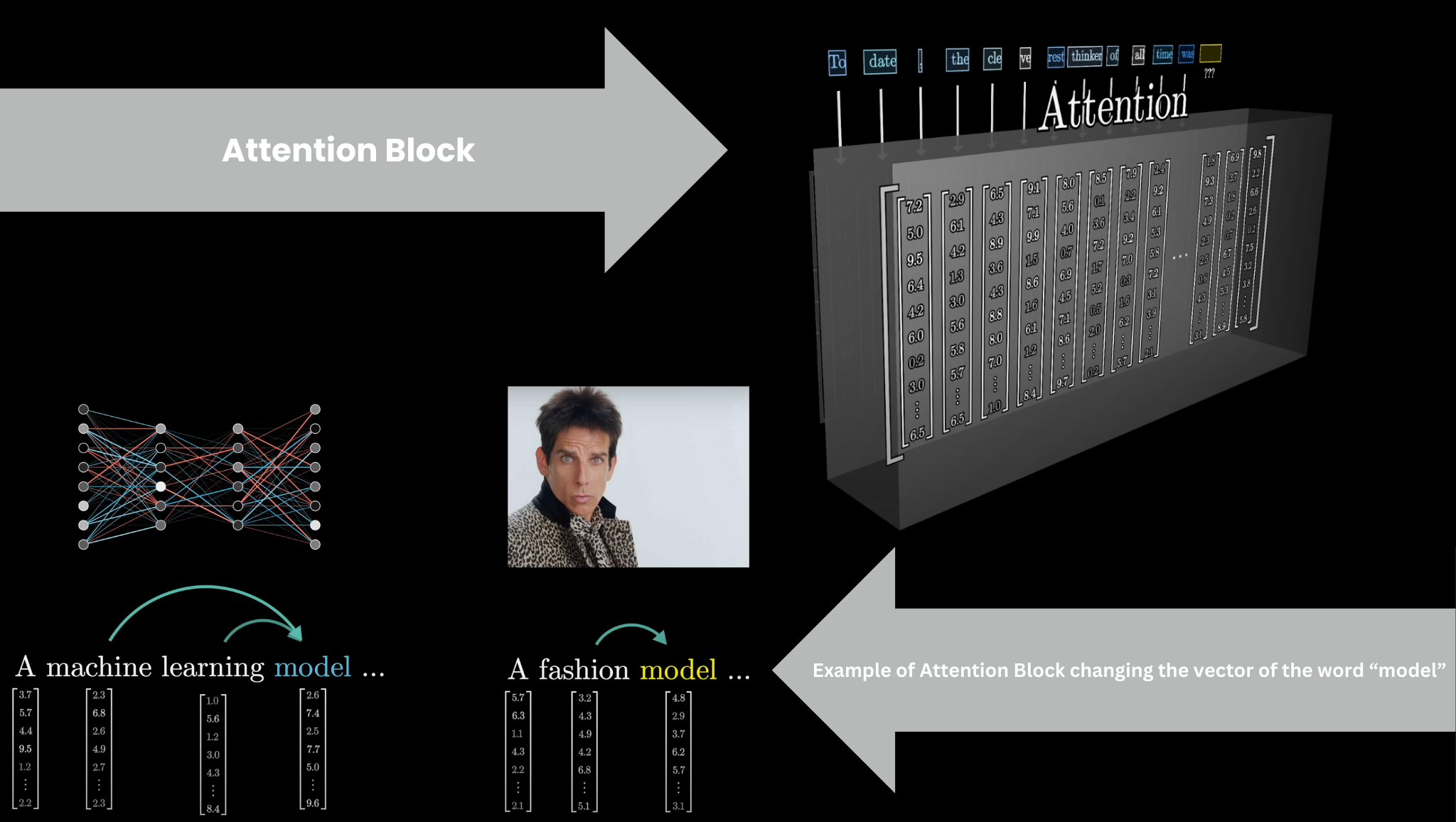
Vectors update each other based on context. “model” in “a machine learning model” vs “a fashion model” — the Attention Block shifts the vector to reflect which meaning applies.
Source: 3Blue1Brown — What is a GPT?
The MLP: asking questions about each vector
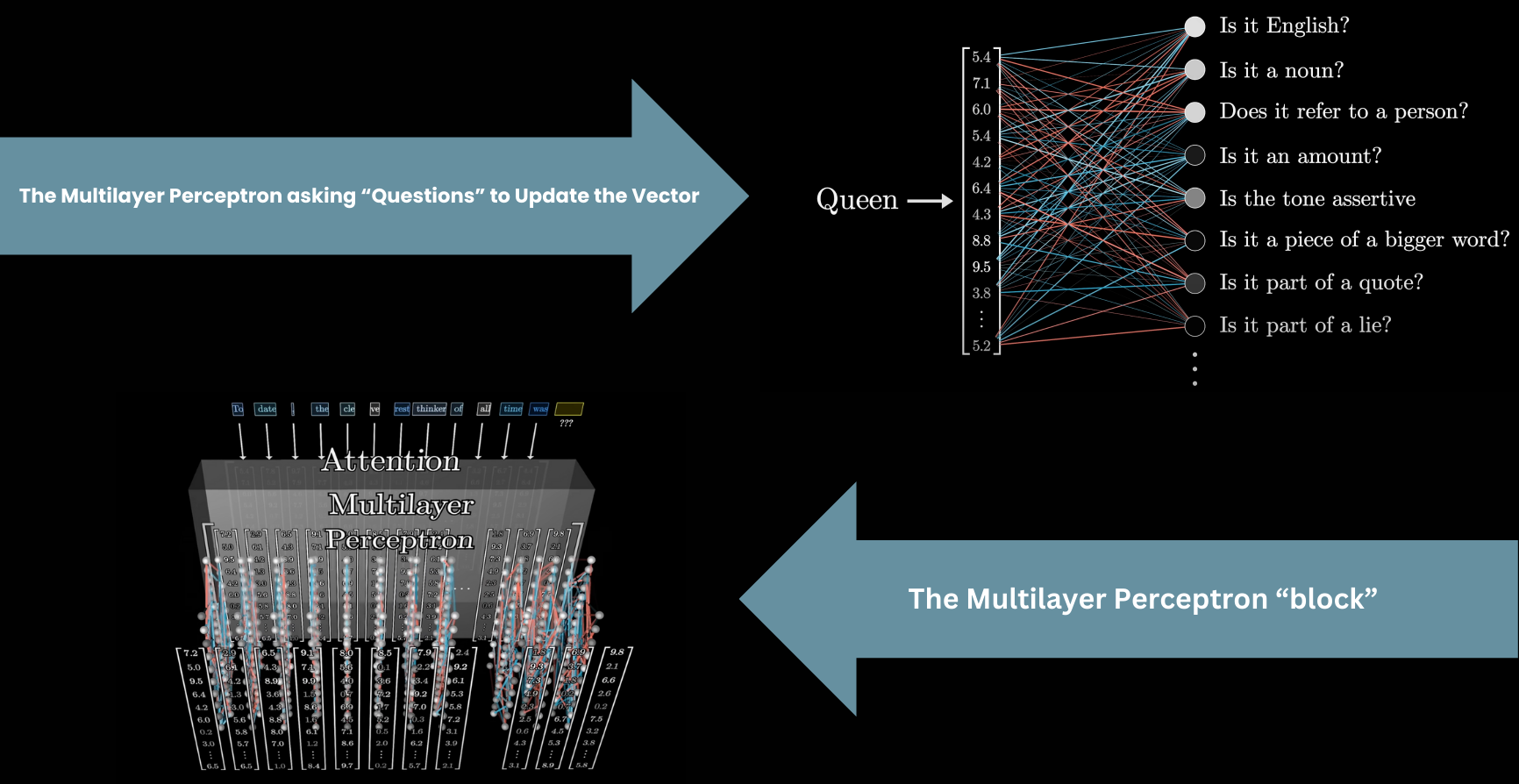
After attention, each vector passes independently through a Multilayer Perceptron — asking a long list of questions to update its value.
This is where factual associations are thought to be stored.
Source: 3Blue1Brown — What is a GPT?