00 · What Is a Large Language Model?
GENE 46100 — Unit 01
2026-04-11
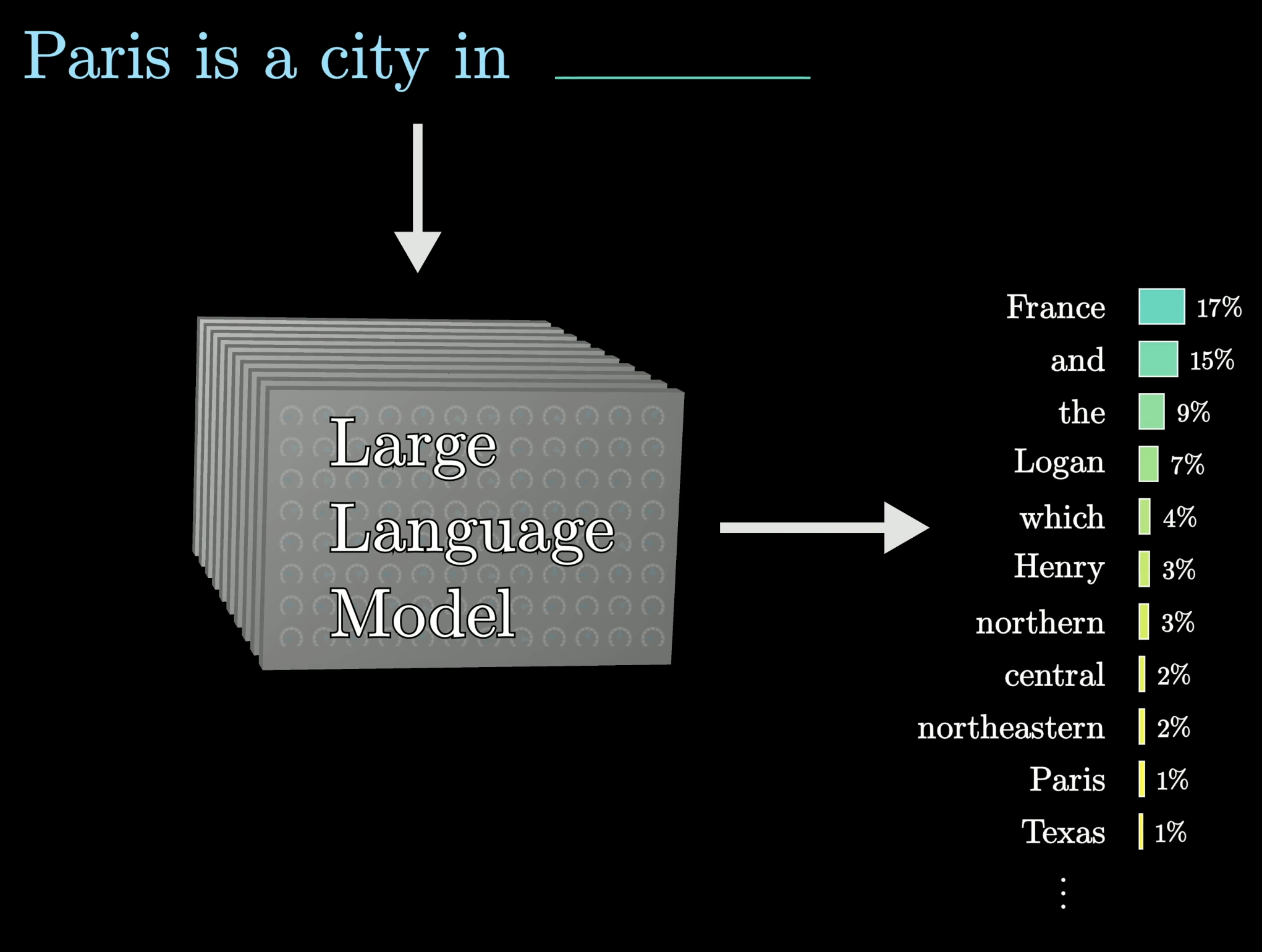
One sentence definition
An LLM is a function that assigns probabilities to the next word in a sequence — not one answer, a whole distribution.
Step 1: The setup — a system prompt
Before your question, the model receives a description of its role.

Step 2: The incomplete script
Your question is appended. The AI’s response is missing — the model must fill it in.

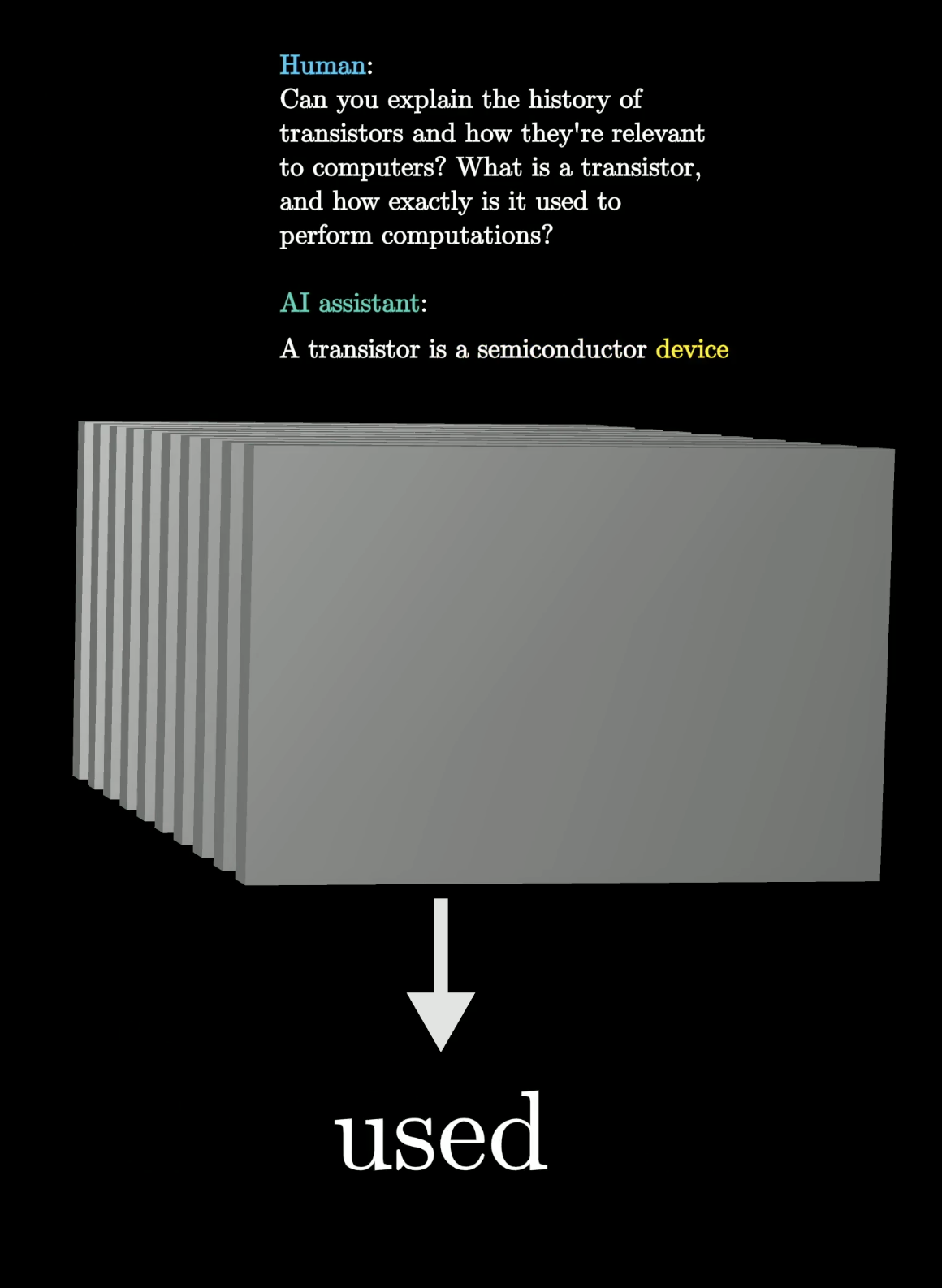
Step 3: Predict one word
The whole text so far is fed into the model. It predicts the most likely next word — here, “used”.
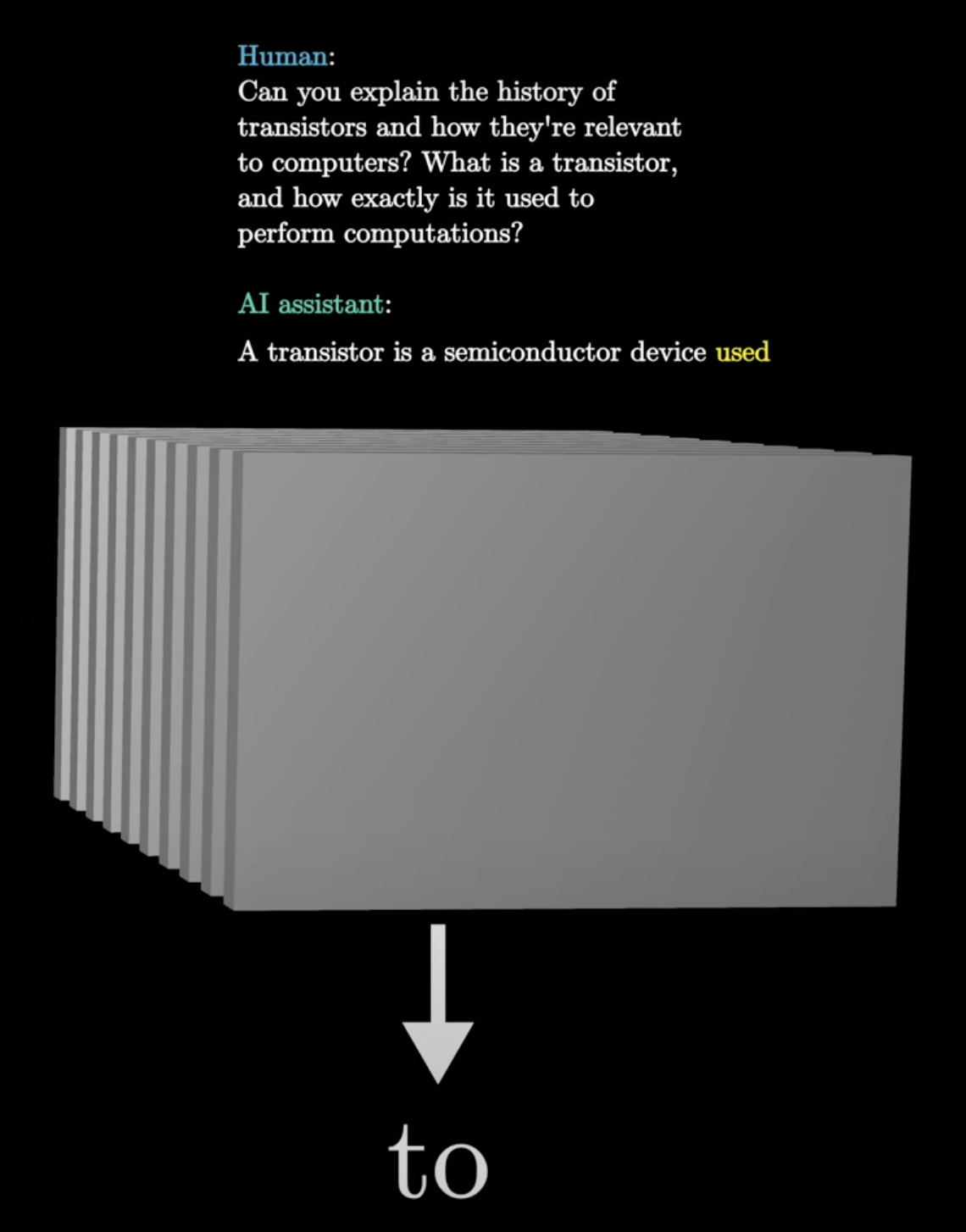
Step 4: Append and repeat
“used” is appended to the script. Feed it all back in. The model now predicts “to”. Repeat.
The full chatbot loop
The model is just completing the script — word by word — until the assistant’s turn is done.

What is the model trained on?
Vast amounts of internet text. Reading GPT-3’s training data would take over 2,600 years of non-stop reading.

What is a “parameter”?
The model is a function with hundreds of billions of tunable dials — parameters. They start at random values and are adjusted through training.
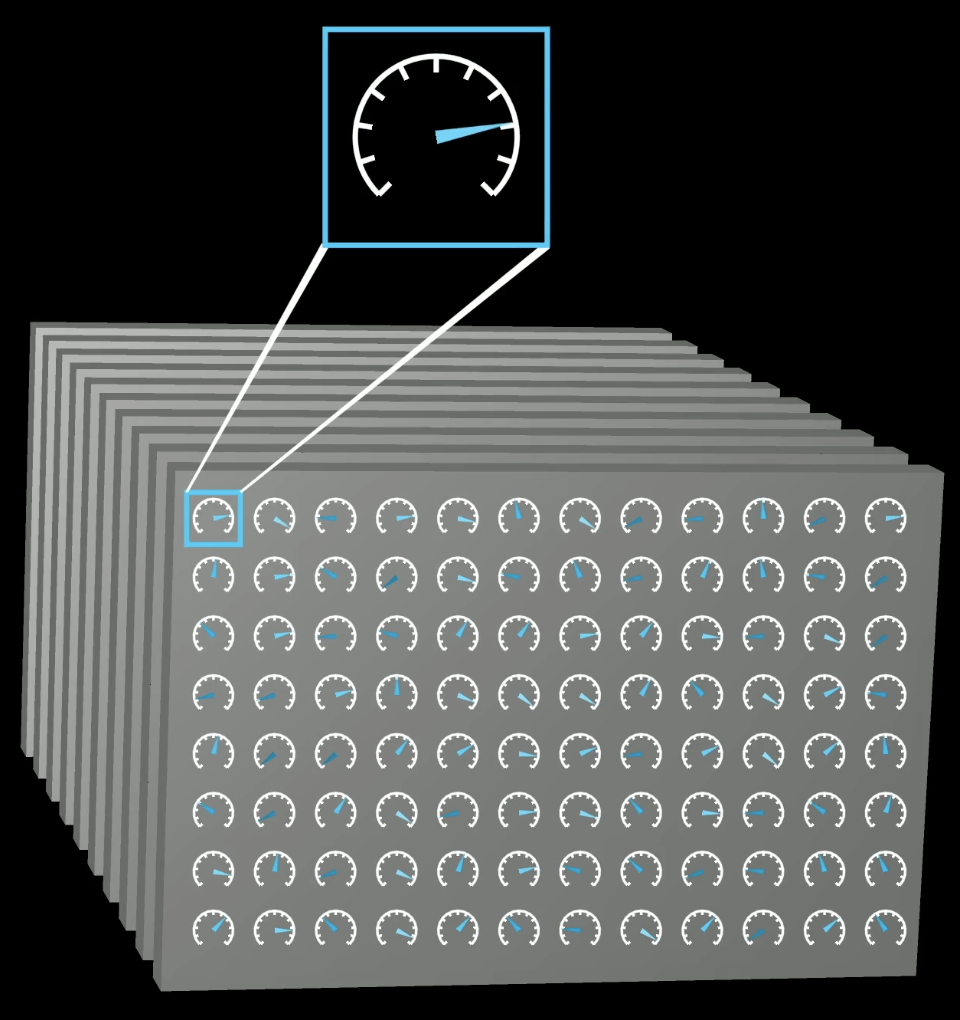
Billions of parameters
Each dial is a continuous number. Their collective setting determines everything the model knows.

The training objective
Show the model text with the last word hidden. Ask it to predict. Compare against the truth.
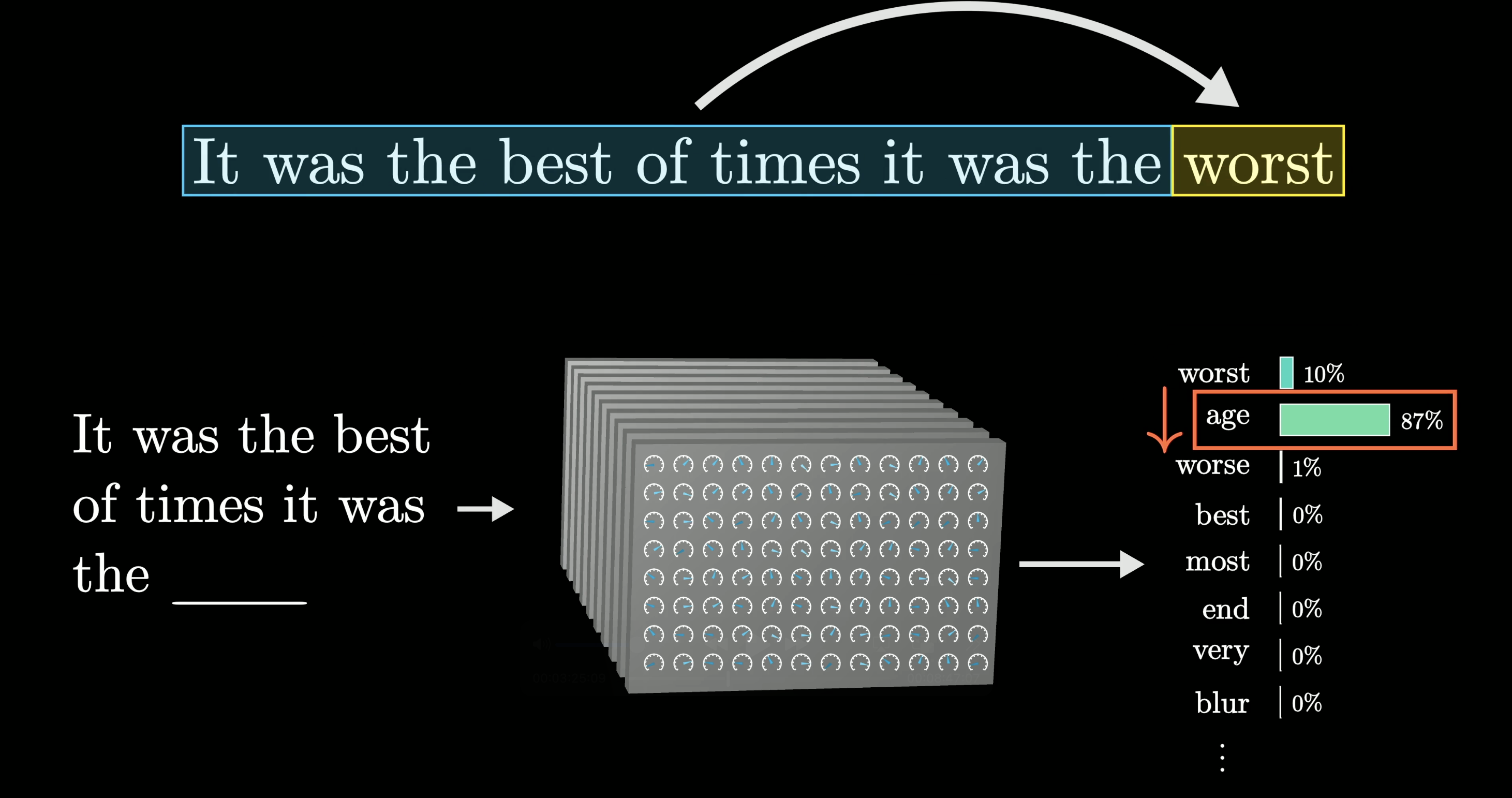
Here: model guesses “age” (87%) when the correct answer is “worst” (10%). It’s wrong.
Backpropagation fixes that
Adjust the parameters so “worst” becomes more likely. Do this across trillions of examples.

After training: “worst” jumps to 70%.
Two phases of training
Training is not one step — it has two distinct phases.

Step 1 — Pre-training: predict next words on raw text → learns language Step 2 — RLHF: human feedback shapes it into a useful assistant
RLHF: Reinforcement Learning from Human Feedback
Human workers review model outputs and flag problematic or unhelpful responses. Those corrections adjust the parameters further.

This is what turns a raw language model into a chatbot.
Why GPUs?
Training requires billions of parallel multiply-and-add operations. GPUs — originally designed for graphics — are built for exactly this.
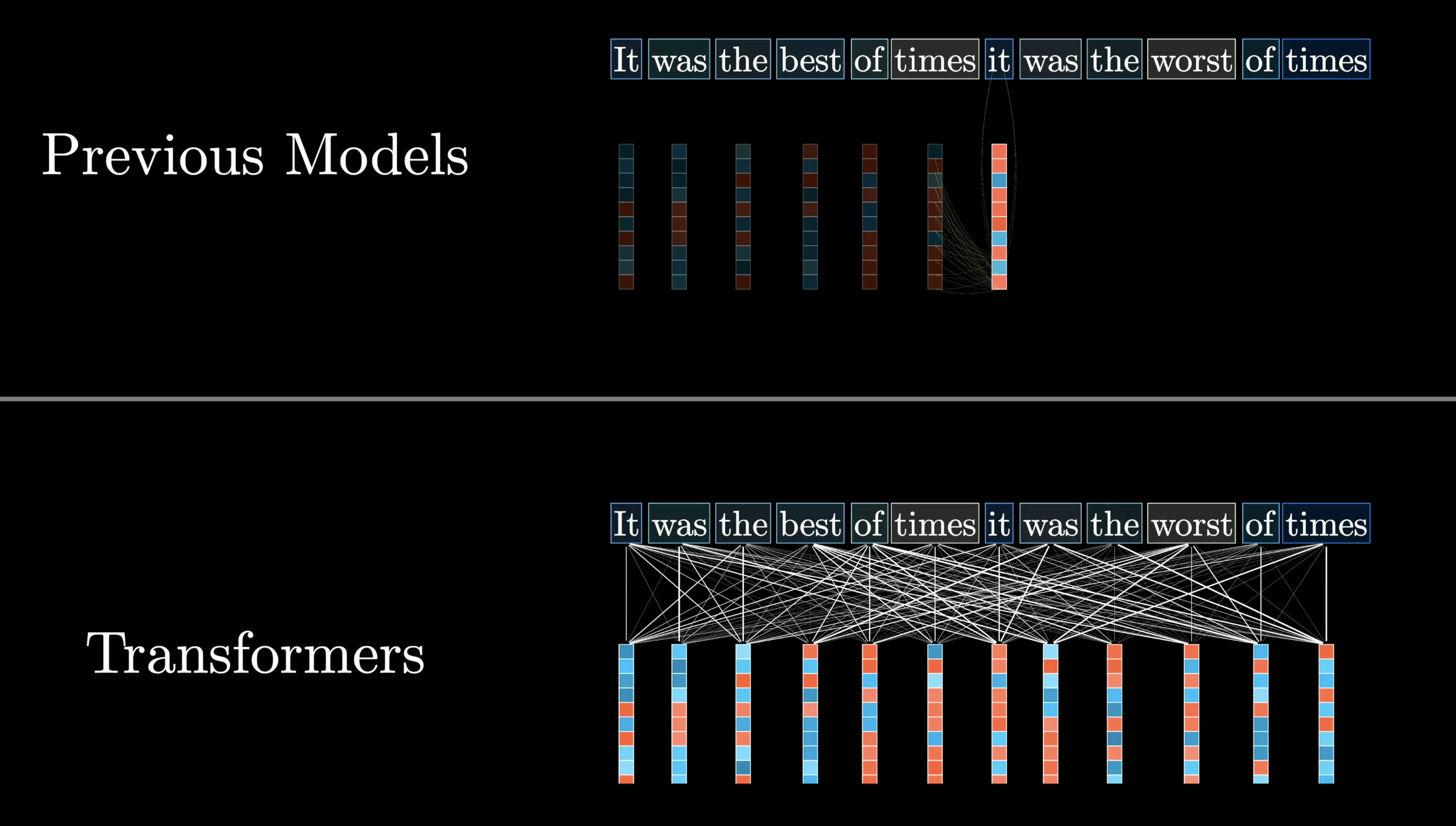
The 2017 breakthrough: Transformers
Before 2017, models processed text one word at a time (sequential). Transformers process the whole sequence at once (parallel).
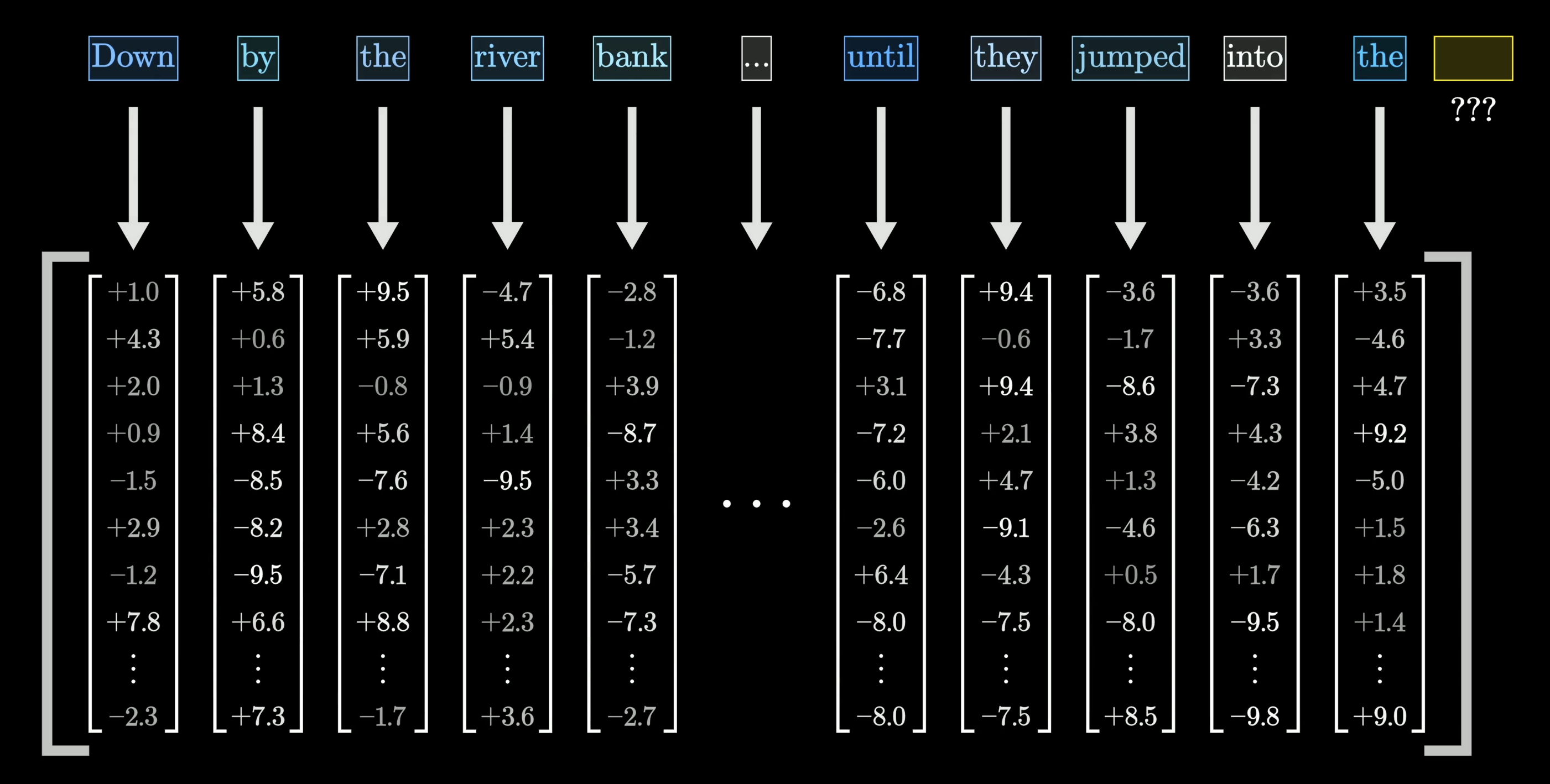
Words → vectors
Each word is mapped to a long list of numbers — a vector. These numbers encode the word’s meaning in a form the model can compute with.
Attention: vectors that communicate
The attention operation lets every vector update itself based on context from other vectors.
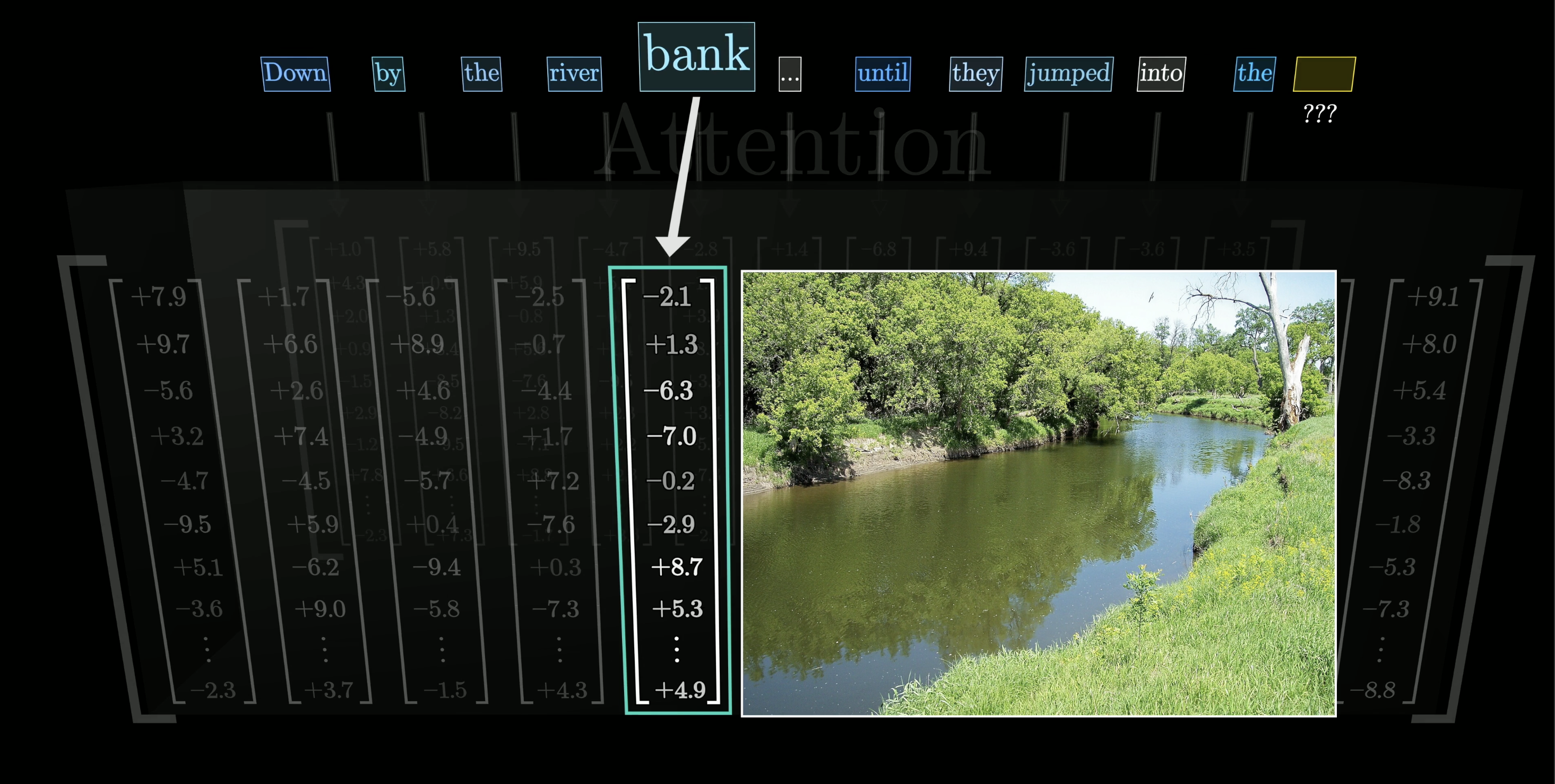
“bank” surrounded by “river” and “jumped into” → the vector shifts to encode riverbank, not financial institution.
Over and over: layers refine meaning
Attention and feed-forward layers alternate, repeatedly. Each pass enriches the vectors.
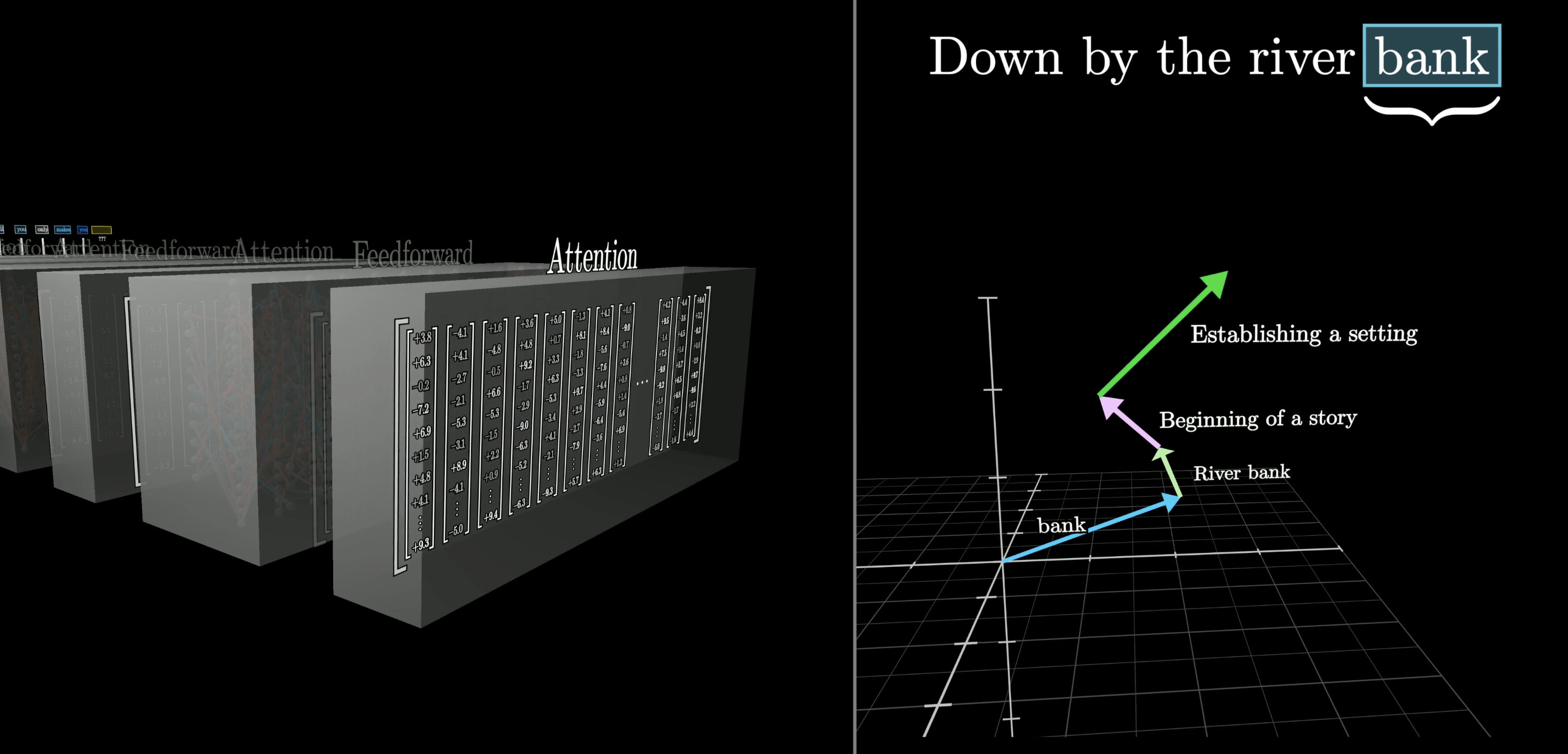
Right: the “bank” vector travels through meaning-space — from the raw token, to riverbank, to narrative context.
The final prediction
After all layers, the last vector encodes everything: context + training knowledge. A final function converts it to a probability distribution.
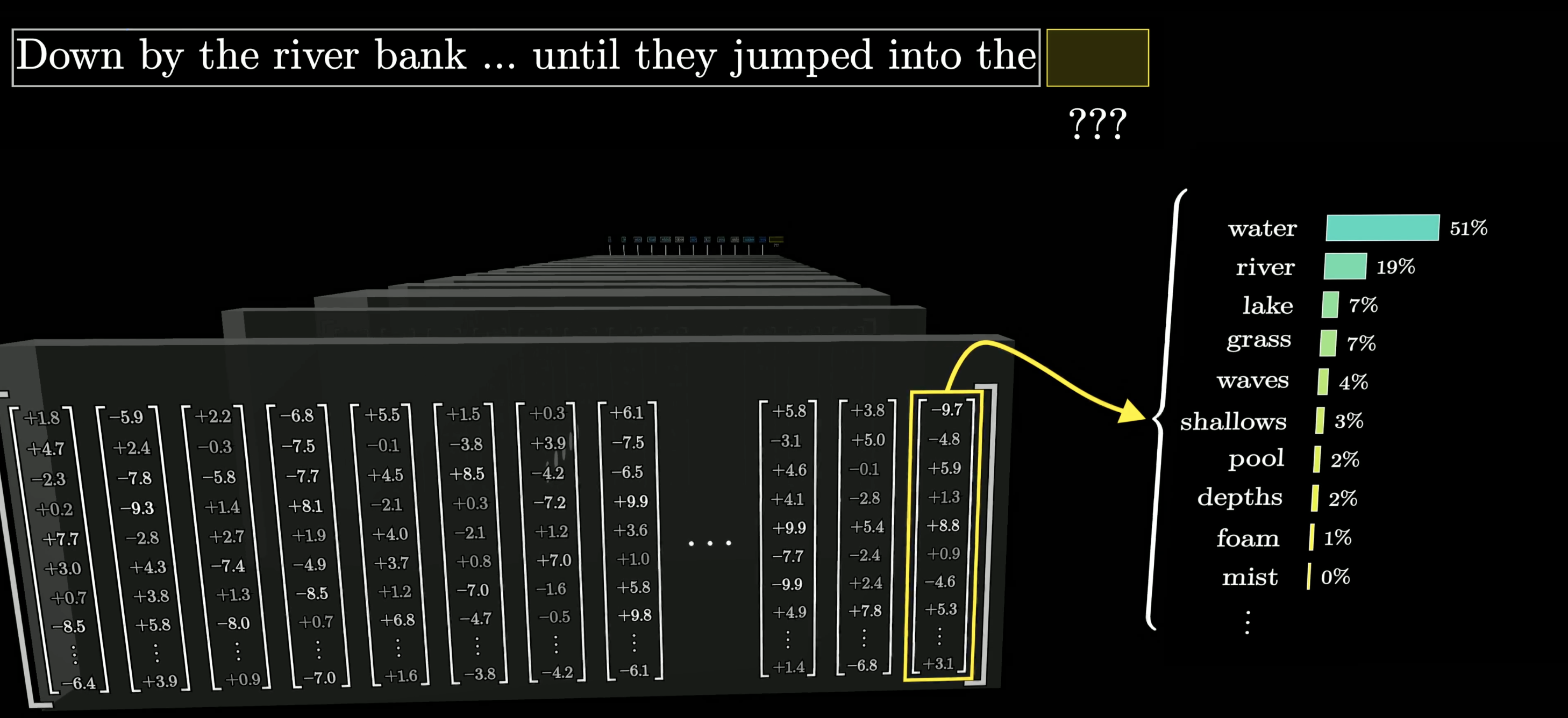
*“Down by the river bank … until they jumped into the ___“* → water: 51%, river: 19%, lake: 7% …